chatGPT 4 - robot octopus, embodied by an AI, holding data science and machine learning tools, colorful underwater, cyberpunk
Exploratory data analysis (EDA) is helpful for summarizing variables, accessing data quality, exploring multivariate trends and refining data analysis strategies.
5.1 Data Summary
When faced with a new data set, a great first step is to identify the types of variables and summarize them. Lets use this as an opportunity to practice the skills we have learned so far. Later we will use some R libraries to take our data summary skills to a new level.
mpg cyl disp hp drat wt qsec vs
"numeric" "numeric" "numeric" "numeric" "numeric" "numeric" "numeric" "numeric"
am gear carb
"numeric" "numeric" "numeric"
#basic summarysummary(data)
mpg cyl disp hp
Min. :10.40 Min. :4.000 Min. : 71.1 Min. : 52.0
1st Qu.:15.43 1st Qu.:4.000 1st Qu.:120.8 1st Qu.: 96.5
Median :19.20 Median :6.000 Median :196.3 Median :123.0
Mean :20.09 Mean :6.188 Mean :230.7 Mean :146.7
3rd Qu.:22.80 3rd Qu.:8.000 3rd Qu.:326.0 3rd Qu.:180.0
Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
drat wt qsec vs
Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
Median :3.695 Median :3.325 Median :17.71 Median :0.0000
Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
Max. :4.930 Max. :5.424 Max. :22.90 Max. :1.0000
am gear carb
Min. :0.0000 Min. :3.000 Min. :1.000
1st Qu.:0.0000 1st Qu.:3.000 1st Qu.:2.000
Median :0.0000 Median :4.000 Median :2.000
Mean :0.4062 Mean :3.688 Mean :2.812
3rd Qu.:1.0000 3rd Qu.:4.000 3rd Qu.:4.000
Max. :1.0000 Max. :5.000 Max. :8.000
Next lets use the skimr library for a quick data overview.
5.1.2skimr
library(skimr)skim(data)
Data summary
Name
data
Number of rows
32
Number of columns
11
_______________________
Column type frequency:
numeric
11
________________________
Group variables
None
Variable type: numeric
skim_variable
n_missing
complete_rate
mean
sd
p0
p25
p50
p75
p100
hist
mpg
0
1
20.09
6.03
10.40
15.43
19.20
22.80
33.90
▃▇▅▁▂
cyl
0
1
6.19
1.79
4.00
4.00
6.00
8.00
8.00
▆▁▃▁▇
disp
0
1
230.72
123.94
71.10
120.83
196.30
326.00
472.00
▇▃▃▃▂
hp
0
1
146.69
68.56
52.00
96.50
123.00
180.00
335.00
▇▇▆▃▁
drat
0
1
3.60
0.53
2.76
3.08
3.70
3.92
4.93
▇▃▇▅▁
wt
0
1
3.22
0.98
1.51
2.58
3.33
3.61
5.42
▃▃▇▁▂
qsec
0
1
17.85
1.79
14.50
16.89
17.71
18.90
22.90
▃▇▇▂▁
vs
0
1
0.44
0.50
0.00
0.00
0.00
1.00
1.00
▇▁▁▁▆
am
0
1
0.41
0.50
0.00
0.00
0.00
1.00
1.00
▇▁▁▁▆
gear
0
1
3.69
0.74
3.00
3.00
4.00
4.00
5.00
▇▁▆▁▂
carb
0
1
2.81
1.62
1.00
2.00
2.00
4.00
8.00
▇▂▅▁▁
Do you recognize the output format? This is the same as we previously created in the data wrangling section. Additional information includes overview of missing values, quantiles and variable histograms. This method is specific for different types.
Notice how we get a separate summary for each variable type.
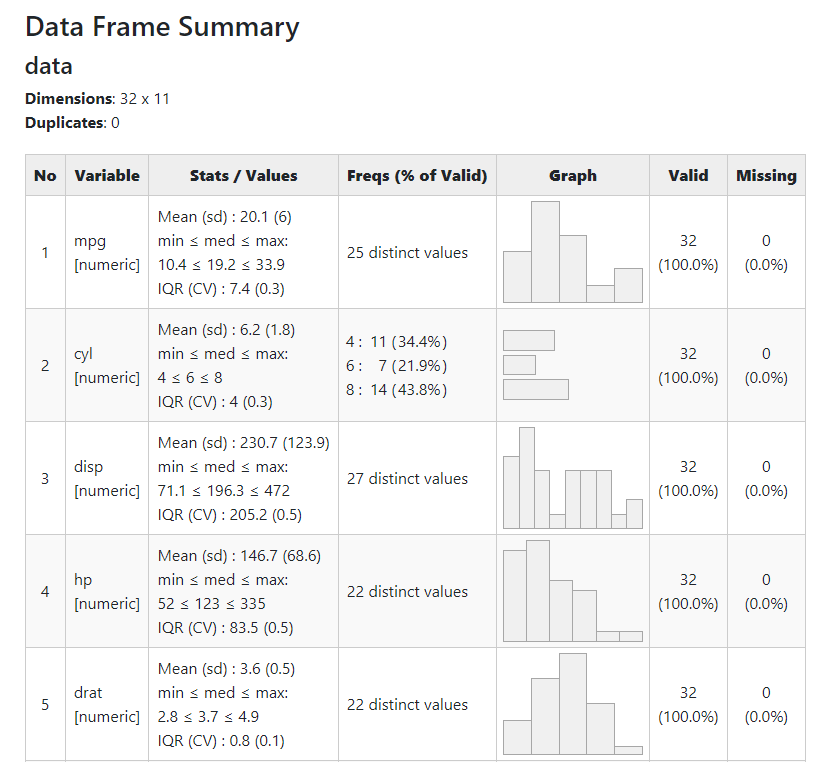
5.2summarytools summary
library(summarytools).summary <-dfSummary(data)# view(.summary) #view html report
5.3 Data Quality
Data quality assessment is an important first step for any analysis. Ideally the experimental design includes replicated quality control samples which can be used for this purpose. For this demo we will assess variability for a grouping variable.
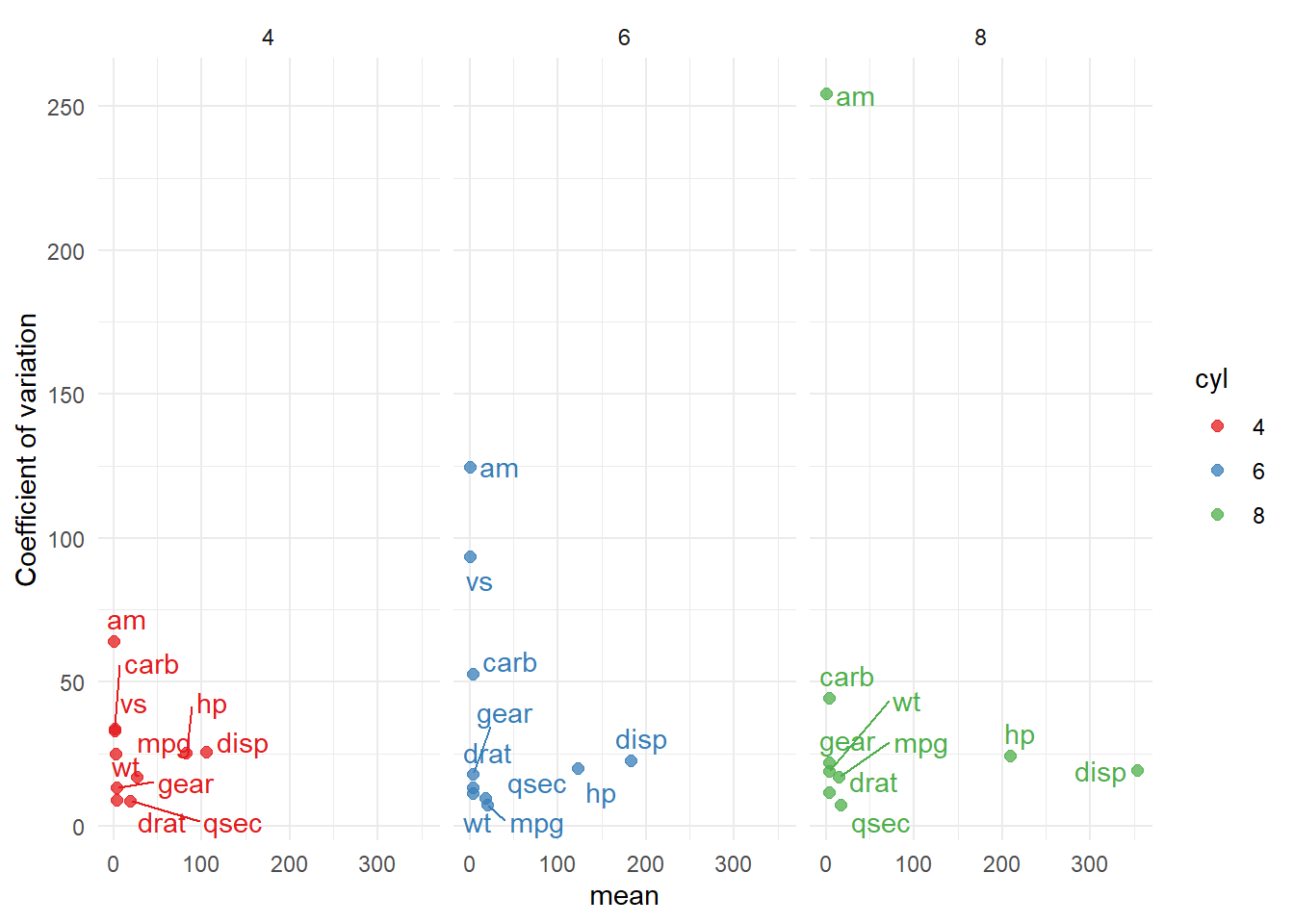
We used group_by to summarize trends for each level of our grouping variable cyl. Notice how the data is formatted. This is referred to as a melted or long data format. Next, lets calculate the coefficient of variation (CV; std/mean) for each column in our data and level of cyl.
Plot the CV vs. the mean for each variable separately for each level of cyl.
library(ggplot2)library(ggrepel)theme_set(theme_minimal()) # set theme globalyoptions(repr.plot.width =2, repr.plot.height =3) # globaly set wiggplot(.summary, aes(x=numeric.mean,y=CV,color=cyl)) +geom_point(size=2, alpha=.75) +geom_text_repel(aes(label=skim_variable),show.legend =FALSE) +facet_grid(.~cyl) +scale_color_brewer(palette ='Set1') +xlab('mean') +ylab('Coefficient of variation')
This plot is useful to identify variables with low precision which may need to be omitted for further analyses. In the case of mtcars we see the variables with high CV compared to their mean should all be categorical. For example we can check that am shows a large differences for levels of cyl.
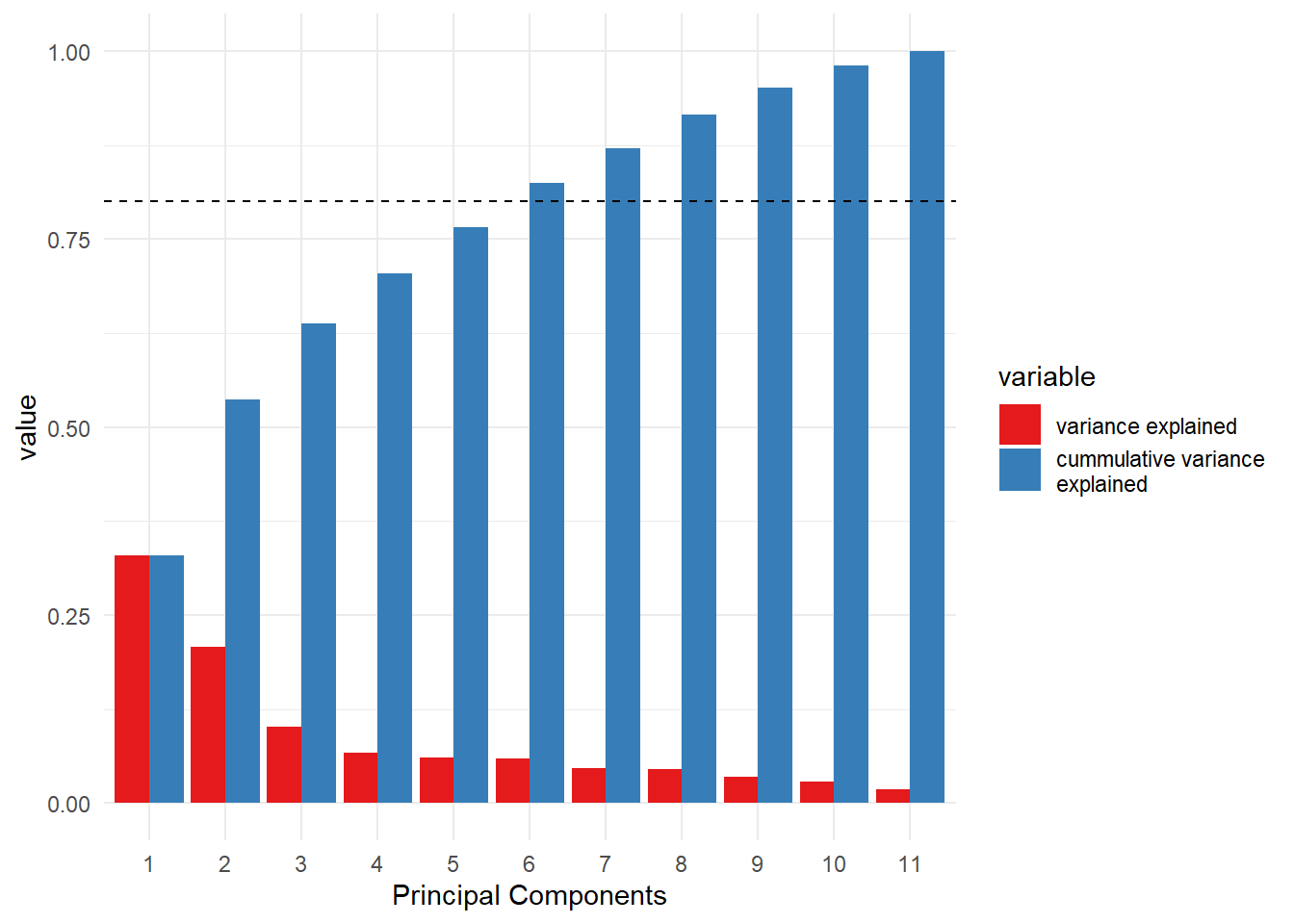
Next lets visualize sample (row) trends given all variables (columns) using principal components analysis (PCA). PCA is a powerful technique to identify unknown patterns and/or evaluate assumptions about your data. First, lets calculate the principal components and visualize their variance explained.
#calculate and show eigenvalue summarypca_obj <-prcomp(data,scale=TRUE)
5.4.1 Visualize optimal principal components (PCs) to retain.
#notice the summary method does not return the results as printed.#we could modify the method todo so or replicate resultseigenvals<-pca_obj$sdeveigenvals_cumsum<-cumsum(eigenvals)var_explained<-sum(eigenvals)prop_var_exp<-eigenvals/var_explainedprop_cumsum<-eigenvals_cumsum/var_explainedpca_eigen<-data.frame(PC=1:length(eigenvals),var_explained=prop_var_exp,eigen_cumsum=prop_cumsum)
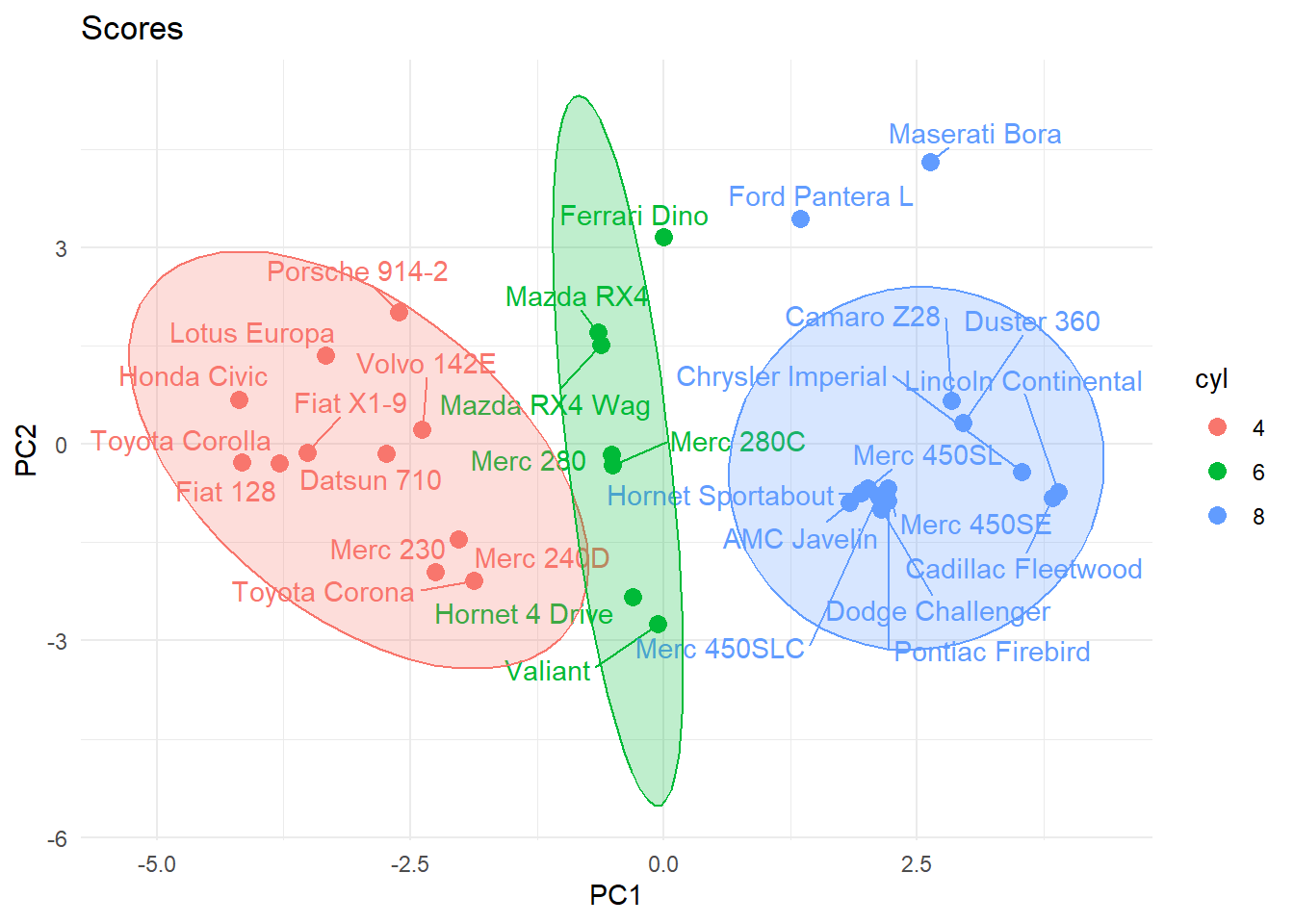
This visualization is helpful for identify similarity within and between different numbers of cyl. For example, we can see that the biggest differences (in variables) are between cyl=4 and cyl=8. If we expect sample scores to be bivariate normal in the scores space, samples outside the ellipses can be helpful for identify moderate outliers among groups of cyl.
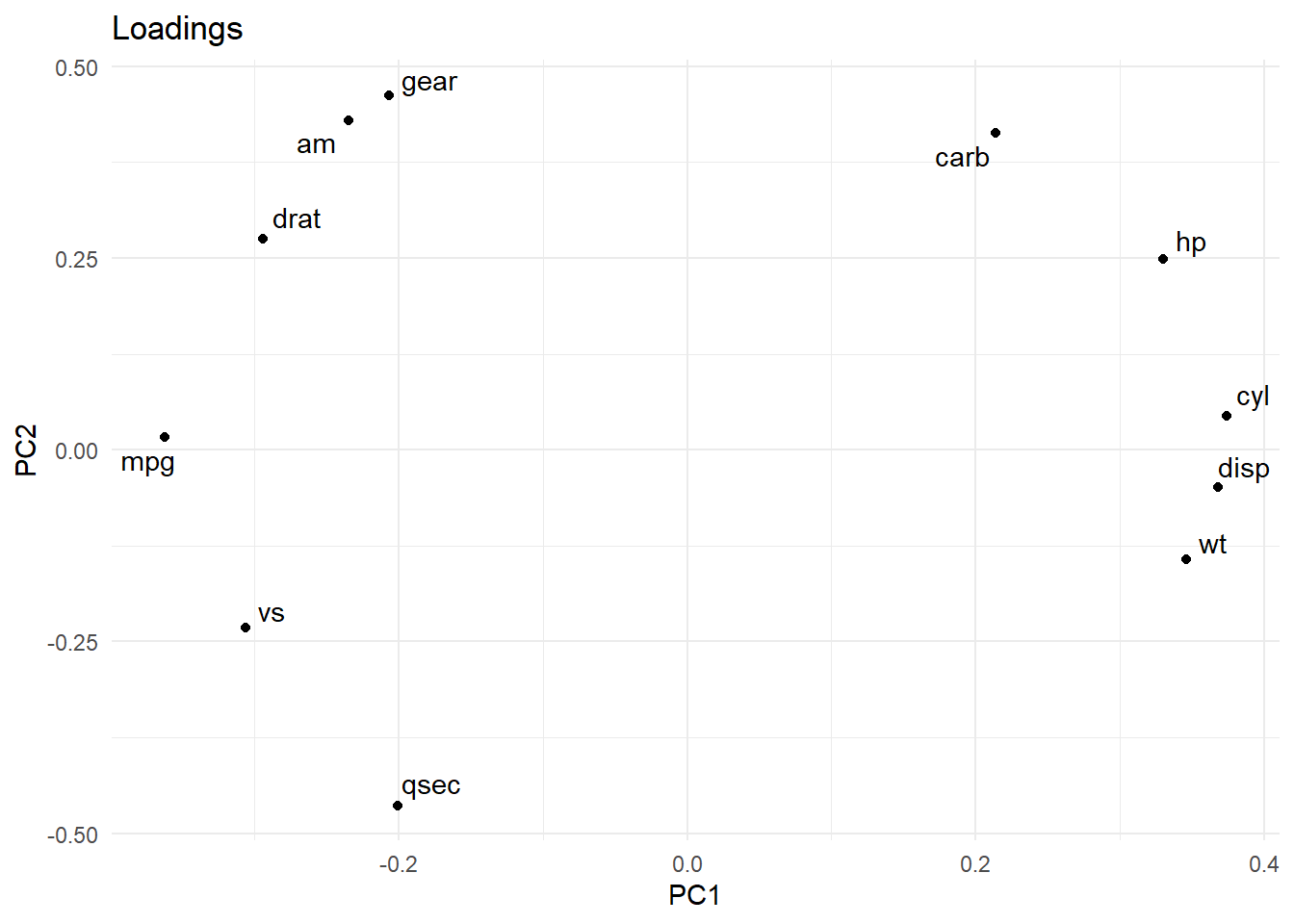
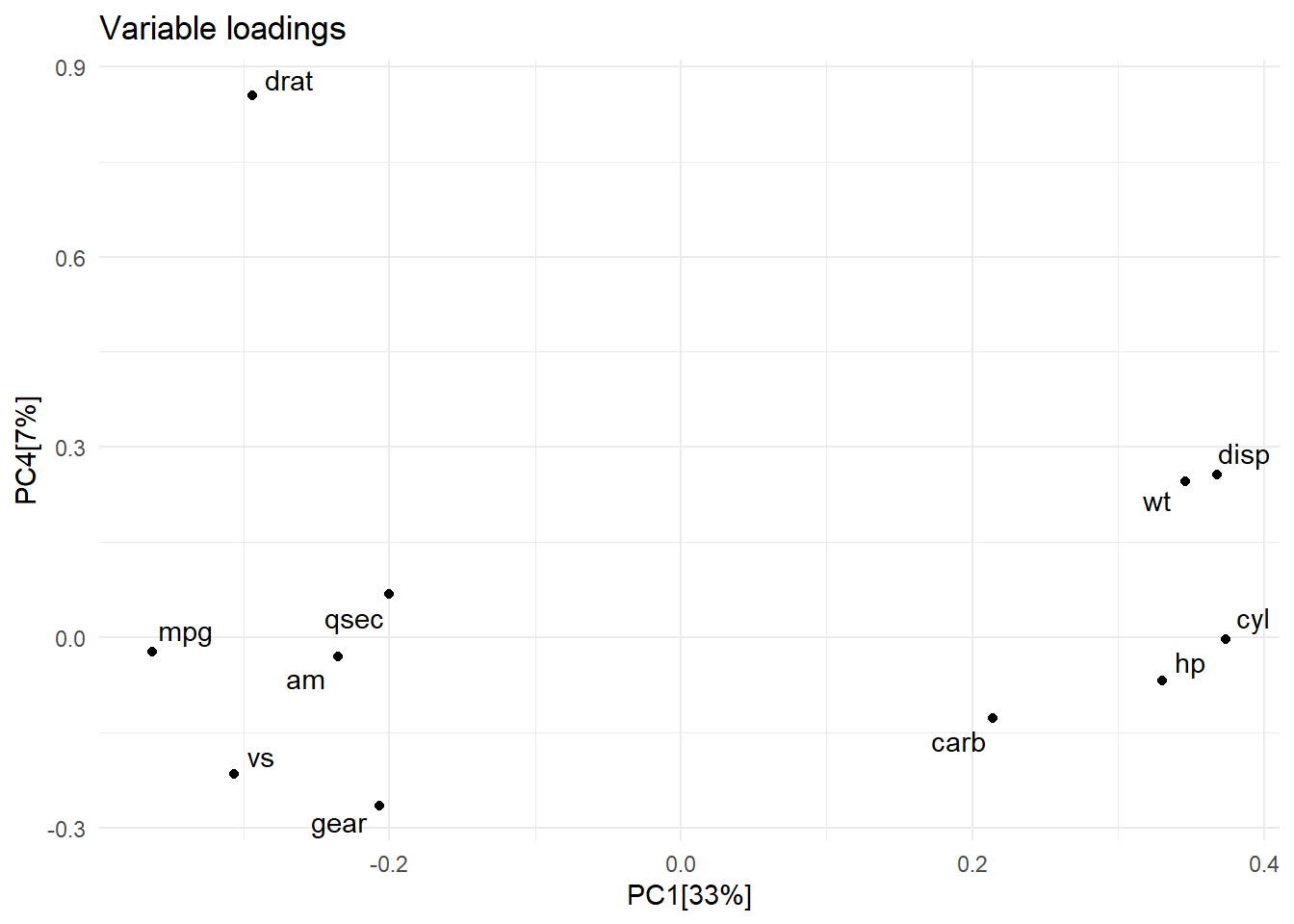
Loadings can be used to identify which variables are most different between groups of sample scores. For example, since groups of cyl scores are spread in the x-axis (PC1) we can look at the variables with largest loadings on PC1 (largest negative and positive PC1 values (position on the x-axis) to identify the largest differences in variables between groups of cyl. This can be useful to identify that cars with smaller number of cyl have higher mpg and lower disp.
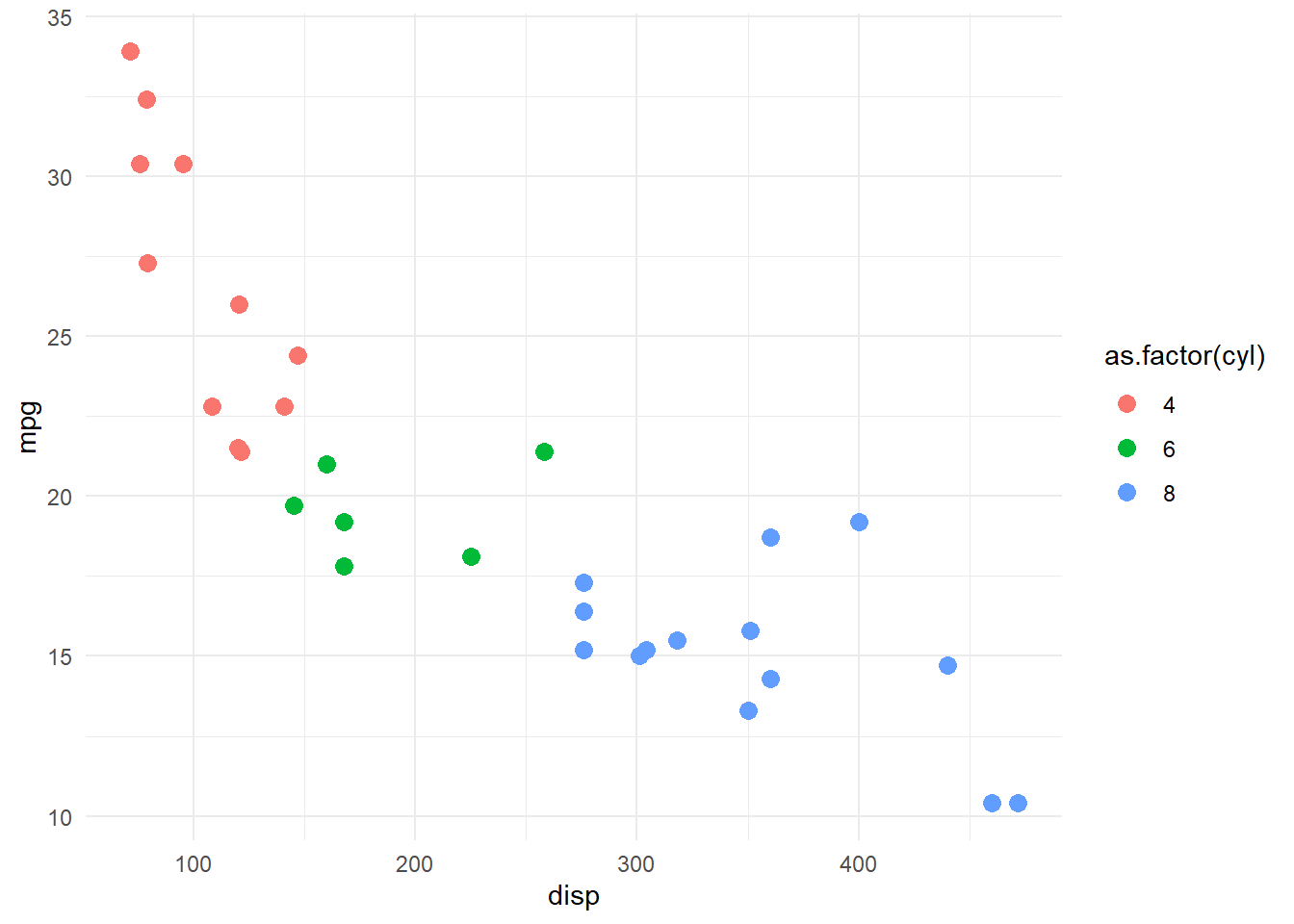
We can investigate this observation by making a custom visualization.
p<-ggplot(mtcars, aes(x = disp, y = mpg,color=as.factor(cyl))) +geom_point(size=3)p
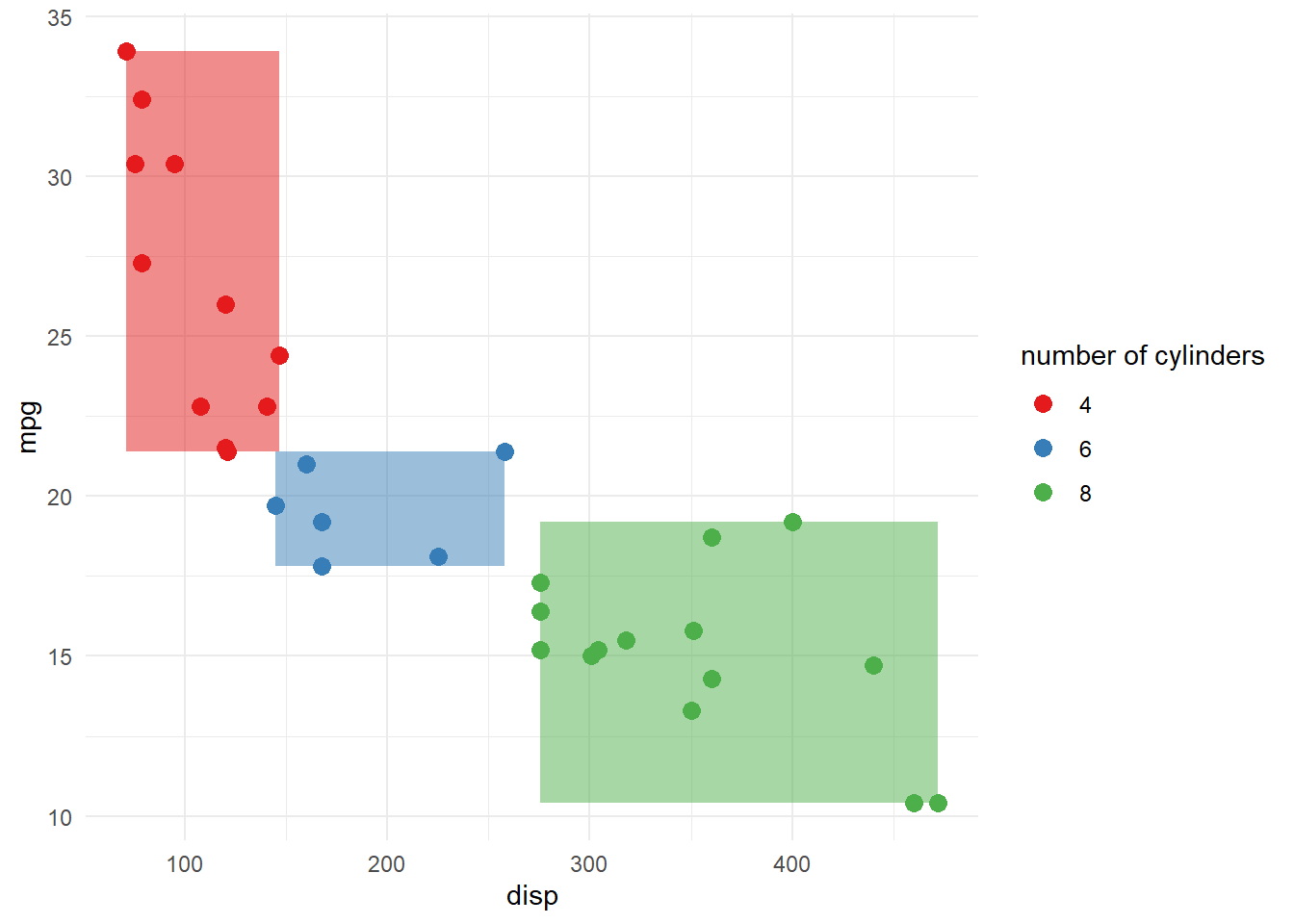
Notice how we can almost perfectly separate groups of cyl based on these two dimensions?
library(tidyr)#calculate min and max for variables given groups of cyl.ranges<-mtcars %>%group_by(cyl) %>%summarise(min_mpg =min(mpg), max_mpg =max(mpg),min_disp =min(disp), max_disp =max(disp)) %>%gather(variable, value, -cyl) %>%separate(variable, into =c("variable", "stat"), sep ="_") %>%spread(stat, value)#add rectangles to the plot#note: this is sub optimal as we need to know what is x or y axis in the plottmp<- .ranges %>%split(., .$cyl)#need to know colors to set rectangle colorsp<-p +scale_colour_brewer(palette ='Set1',aesthetics ="colour")#get color codeslibrary(RColorBrewer).colors<-brewer.pal(length(levels(mtcars$cyl)), 'Set1')for(x in1:length(tmp)){ i<-tmp[[x]] xmin<- i %>%filter(variable =='min') %>%select(disp) %>% .[1,,drop=TRUE] xmax<- i %>%filter(variable =='max') %>%select(disp) %>% .[1,,drop=TRUE] ymin<- i %>%filter(variable =='min') %>%select(mpg) %>% .[1,,drop=TRUE] ymax<- i %>%filter(variable =='max') %>%select(mpg) %>% .[1,,drop=TRUE]p<-p +annotate("rect", xmin = xmin , xmax = xmax, ymin = ymin, ymax = ymax,alpha = .5,fill = .colors[x])}p +guides(color=guide_legend(title="number of cylinders"))